This page provides an introduction to the AI Stack, outlining its key components and benefits. It serves as a starting point for understanding the foundational elements of AI technology.
The remarkable progress in AI and ML is deeply intertwined with the sweeping changes that have reshaped the hardware industry. At the heart of these advancements lie key driving factors that pushed the boundaries of what was possible, setting the stage for groundbreaking innovations. These factors have acted as catalysts, transforming the very foundation of computational infrastructure to meet the ever-growing demands of modern technology. To understand how we arrived at this point, it is essential to explore the pivotal forces that have not only driven but also defined the trajectory of the hardware industry, fueling the technological leaps we now take for granted.
1. Moore’s Law and Its Moot Point
For decades, Moore’s Law served as a beacon for the semiconductor industry, predicting the biennial doubling of transistors on microchips. However, as we push the boundaries of silicon technology, the physical limitations of thermodynamics and quantum mechanics have challenged this exponential growth. The result? A paradigm shift in how we approach computing power, especially in the realm of artificial intelligence (AI).
2. The Evolution of AI/ML Workloads
In the past decade, AI and machine learning workloads have grown from relatively modest tasks like image and speech recognition to complex natural language processing and decision-making models. The emergence of deep learning and neural networks drove the need for more computational power, with large corporations like Google, Facebook, and OpenAI leading the charge in developing proprietary models on specialized hardware.
3. The Rise of Large Language Models
The introduction of ChatGPT marked a pivotal moment, showcasing the capabilities of large language models. This sparked a surge of interest in generative AI, driving a demand for hardware capable of supporting the massive computational needs of these models. The rise of open-source large language models has democratized access, allowing a broader audience to experiment and innovate. This shift has intensified the demand for powerful AI hardware, pushing the boundaries of what’s possible in machine learning and AI development.
Pack More, Move More and Move More, Faster
To understand the architectural challenges and needs in AI hardware, we can categorize them into three main areas: Pack More, Move More, and Move Faster. Each area reflects a different aspect of chip design, highlighting the constant struggle to overcome physical limits while pushing performance boundaries.
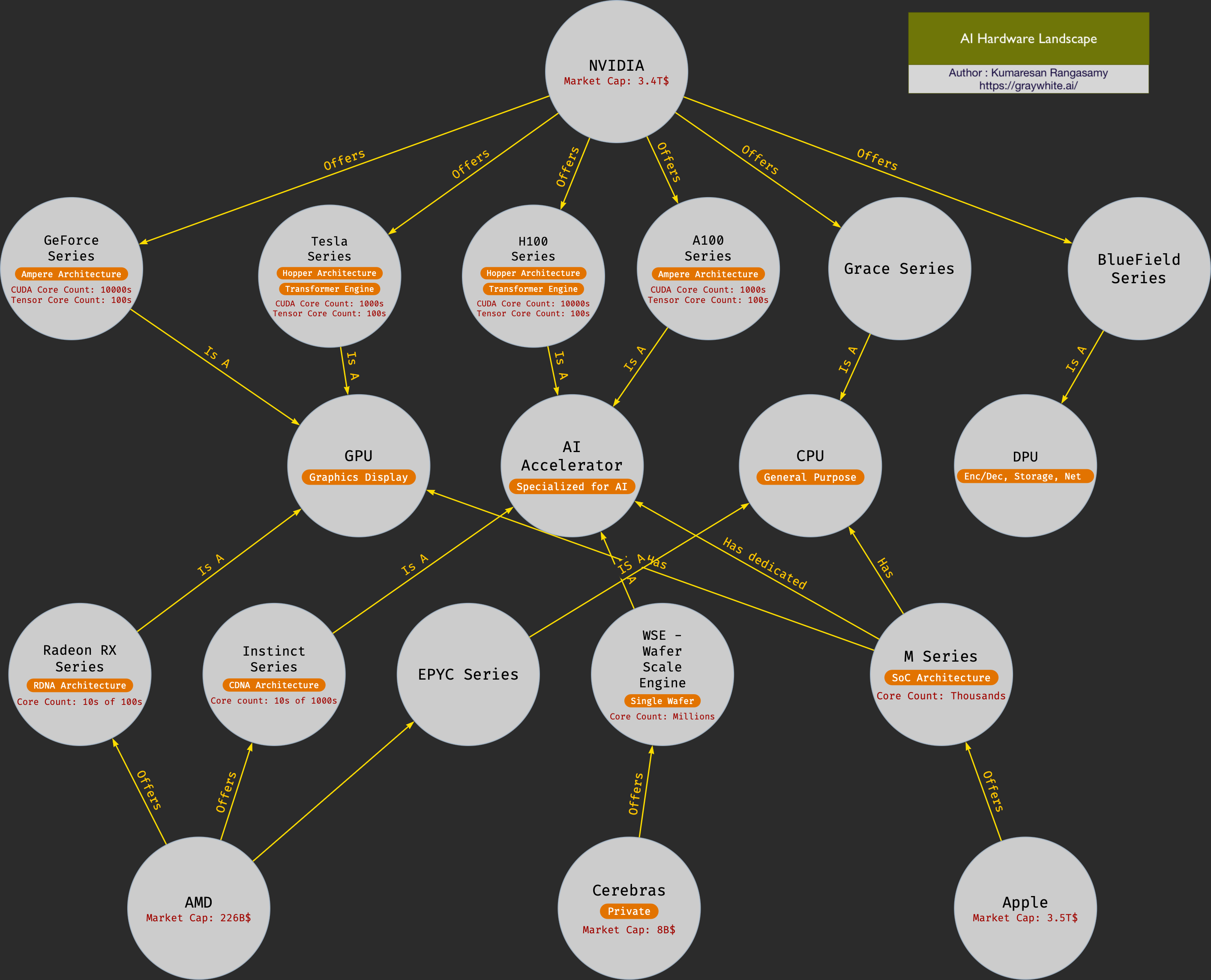
Understanding the Hardware: GPU, DPU, and Specialized Accelerators
To appreciate the advancements in AI hardware, it’s essential to understand the key components driving this progress. Graphics Processing Units (GPUs), originally designed for rendering images, have become the cornerstone of AI computations due to their parallel processing capabilities. Data Processing Units (DPUs) and specialized accelerators have further optimized data handling and model training processes, catering to the growing needs of AI applications. These hardware innovations are at the heart of modern AI infrastructure, enabling the realization of AI’s full potential.
1. Pack More: Increasing Core Density on a Single Chip
The Need: As AI models grow in complexity, they demand more computational power. To meet this demand, chip designers are adding more cores (CUDA cores, Tensor cores, Matrix cores) onto a single chip. Each core can handle parallel tasks, which allows GPUs to process vast amounts of data simultaneously.
The Challenge: Packing more cores tightly into a chip increases power consumption and generates a significant amount of heat. According to the law of thermodynamics, as more energy is used (in the form of electricity), more heat is generated. This creates a thermal management problem — there’s only so much heat that a chip can dissipate before it overheats and loses efficiency.
Limitations: The physics of heat dissipation and power density create a hard limit on how many cores can be packed into a single chip without advanced cooling solutions.
Solutions Being Explored:
- Mixed Precision: Using lower-precision calculations where possible (e.g., FP16 or FP8) reduces the power each core consumes, allowing more cores to operate without generating excessive heat.
- Advanced Cooling: Liquid cooling, specialized air cooling, and even immersion cooling are being explored to keep densely packed chips at optimal temperatures.
- Chiplet Architectures: Breaking up a large chip into smaller “chiplets” can improve thermal distribution and make manufacturing more manageable.
2. Move More: Enhancing Data Movement Between GPU and Memory, and Between Multiple GPUs
The Need: AI workloads require enormous datasets, which need to be constantly moved between memory and processing cores. Additionally, in data center environments with multiple GPUs working together, inter-GPU communication is essential for tasks that require distributed processing, like large model training. The ability to move more data quickly is crucial to keeping all cores active and avoiding bottlenecks.
The Challenge: Moving large volumes of data creates bottlenecks in memory bandwidth and interconnect bandwidth. Physically, data can only travel so fast over wires and through interconnects. The laws of physics, particularly signal degradation over long distances, limit how much data can be moved and at what speed.
Limitations: High data volumes lead to increased latency, limited by the physical distances between memory, cores, and other GPUs. The more data that needs to move, the greater the chance for latency and bottlenecks, which slow down overall processing.
Solutions Being Explored:
- High-Bandwidth Memory (HBM): Using memory with high data transfer rates (like HBM2 or HBM3) allows more data to be moved to and from the GPU with less latency.
- Interconnect Technologies: NVIDIA’s NVLink, AMD’s Infinity Fabric, and Intel’s Omni-Path are specialized interconnects designed to facilitate high-speed data movement between GPUs. These interconnects minimize the delay and increase the effective data throughput for multi-GPU setups.
- Unified Memory Architectures: For devices like Apple’s M-series, unified memory allows the CPU, GPU, and other processors to share a single pool of memory, reducing data movement needs between discrete memory modules.
3. Move Faster: Reducing Latency in Data Transfers
The Need: Even if you can “move more” data, it also needs to be moved quickly enough to keep up with the processing speed of the cores. Latency in data movement can cause cores to sit idle, waiting for data to arrive, which reduces overall performance. Faster data transfer allows GPUs to maximize their compute power and handle more tasks without delays.
The Challenge: Moving data quickly is constrained by the laws of physics and signal propagation delay. Data can only travel so fast across wires, and long distances or inefficient interconnects slow down the process. Additionally, with high frequencies, signal integrity becomes a concern, as high-speed signals are more susceptible to noise and interference.
Limitations: You can only achieve so much speed before hitting physical constraints in signal propagation and distance. The closer memory is to the cores, the less time it takes for data to reach them, but proximity is limited by chip design.
Solutions Being Explored:
- Proximity Optimization: Placing memory modules and cores closer together on the chip minimizes the distance data needs to travel, reducing latency.
- Low-Latency Interconnects: Technologies like PCIe 5.0, NVLink 4.0, and Infinity Fabric are engineered to minimize latency by optimizing the data transfer pathways and increasing bandwidth.
- On-Chip Memory Buffers: Some architectures integrate small memory buffers directly on the chip, allowing for quick access to frequently needed data without traveling to and from the main memory.
4. Summary of the Three Approaches
| Aspect | Goal | Challenges (Physical Limits) | Examples of Solutions |
|---|---|---|---|
| Pack More | Increase core count for higher parallel processing | Power density, heat dissipation (thermodynamics) | Mixed precision, chiplet design, advanced cooling |
| Move More | Increase data transfer volume between memory and GPUs | Bandwidth limits, signal degradation over distance (physics) | High-bandwidth memory, interconnects (NVLink, Infinity Fabric) |
| Move Faster | Reduce latency in data transfer | Signal propagation delay, distance limitations (speed of signals) | Proximity optimization, low-latency interconnects, on-chip buffers |
In summary, as AI models become larger and more demanding, each of these three areas — Pack More, Move More, and Move Faster — faces challenges rooted in fundamental physics. Companies are pushing technological innovation to overcome these limits, exploring new architectures, materials, and cooling solutions. But as we reach the boundaries of physics, new paradigms like quantum computing, optical interconnects, and novel materials may eventually redefine how we approach these challenges in AI hardware.
Hardware AI Hardware Machine Learning Deep Learning GPUs DPUs AI Accelerators Moore's Law High-Bandwidth Memory Interconnect Technologies AI Infrastructure Computational Power Thermal Management Data Transfer Latency Reduction